
Sora, die Video-AI von OpenAI ist da!

Seit heute ist Sora offiziell auch in der EU verfügbar. Sora ist eine generative KI, die Videosequenzen erstellen kann und ist ein weiteres Produkt von OpenAI. OpenAI kennst du sicher schon als das Unternehmen, das hinter ChatGPT steckt. Aber was ist so besonders an Sora, wie funktioniert die KI und was sind die Anwendungszwecke?
Kurzer Exkurs: Was ist Sora?
Innerhalb kürzester Zeit hat generative KI in Form von Chatbots wie ChatGPT nicht nur die öffentliche Wahrnehmung und den Diskurs in der Gesellschaft beeinflusst, sondern nachhaltigen neue Möglichkeiten der Informationsgewinnung, Auswertung und Verarbeitung geschaffen.
Bereits heute können viele Tätigkeiten effizienter gestaltet werden und somit auch wirtschaftliche Potentiale erschlossen werden.
Während auch KI-gestützte Bilderstellung bereits weit verbreitet ist, steckt die automatische Videoerzeugung noch in den Kinderschuhen. Sora verspricht, genau diese Lücke zu schließen und komplexe, realistische Bewegungsabläufe direkt aus einfachen Textanweisungen zu erstellen. Dadurch eröffnen sich völlig neue Möglichkeiten für Filmemacher, Werbetreibende, Content Creator und Entwickler, die in Sekundenschnelle visuelle Inhalte erschaffen möchten.
Bisher ist Sora nur außerhalb der EU bzw. über Umwege wie VPN nutzbar gewesen.
Nun ist das Tool offiziell auch in der EU und Deutschland freigegeben:
Sora ist also eine KI, die aus Texteingaben Videos generiert. Man nennt das auch eine Text-To-Video KI. Du gibst der KI ähnlich wie bei ChatGPT einen Input in Textform oder eine Quelle als Webseite und die KI erstellt dann nach deinen Anweisungen ein Video.
Für wen ist Sora interessant? Wer ist die Zielgruppe?
Ganz grundsätzlich ist Sora ersteinmal für alle Bereiche interessant, in denen Videoproduktion stattfindet und mit visuellen Inhalten gearbeitet wird. Das geht von Social-Media und der Werbeindurstrie über die Unterhaltungsindustrie bis hin zu Bildungsinstitutionen.
Durch potentielle Kostensenkungen in der Videoproduktion und das Automatisierungspotential erschließen sich aber auch ganz neue Bereiche.
Was sind die konkreten Anwendungsfälle für Sora?
1. Content Creator & Social Media Marketer
YouTuber, TikTok-Creator & Social-Media-Manager können animierte Videos & Werbeinhalte viel schneller und kostengünstiger erstellen.
Beispiel: Werbekampagnen ohne teure Dreharbeiten – einfach per Textanweisung generiert.
2. Filmemacher & Animationsstudios
Regisseure/Animatoren/Produzenten können Prototypen von Szenen erstellen oder sogar ganze Kurzfilme generieren.
Beispiel: Storyboard-Visualisierung, um schnell verschiedene Szenenideen auszuprobieren.
3. Spieleentwickler & Virtual Production
Game-Studios könnten KI-generierte Cutscenes, Hintergründe oder Animationen nutzen. Oder Trailer für neue Produktionen mit entsprechenden Spots garnieren.
Beispiel: Schnelle Erstellung von Umgebungen oder Ingame-Sequenzen ohne aufwendiges Rendering.
4. Bildung & Wissenschaft
Lehrer & Forschende können wissenschaftliche Animationen & Erklärvideos einfacher produzieren. Studien haben gezeigt, dass die mediale Aufbereitung komplexer Zusammenhänge einen großen didaktischen Wert hat.
Beispiel: Physikalische Simulationen oder historische Rekonstruktionen.
5. Unternehmen & Werbung
Unternehmen & Werbeagenturen können KI-gestützte Werbespots, Präsentationen & Produktdemos erstellen.
Beispiel: Maßgeschneiderte Werbevideos, die mit nur wenigen Eingaben personalisiert werden.
Sora in der Praxis
Ich habe Sora ausprobiert, zunächst einmal mit ganz simplen Prompts, ohne große Details oder Prompt Engineering:

Die Oberfläche von Sora ist der von ChatGPT sehr ähnlich und einfach gestaltet. Zwar gibt es ein paar zusätzliche Optionen, der Großteil der Interaktion findet aber über ein einfaches Textfeld statt, in dem man seine Prompts eingibt.
Im obigen Beispiel habe ich Sora z.B. angewiesen, ein kurzes Imagevideo zu einer Webseite (in diesem Fall unserer Stellenbörse) zu erstellen. Keiner weiteren Angaben, die KI quasi ins kalte Wasser geworfen.
Sora beginnt dann mit der Generierung von – in diesem Fall – wie aus ChatGPT bekannt zwei Videovarianten anhand des übermittelten Prompts. Wie man sich denken kann, ist die Generierung eines Videos etwas aufwändiger als eine reine Textausgabe, daher benötigt die KI hier etwas länger für die Ausgabe.
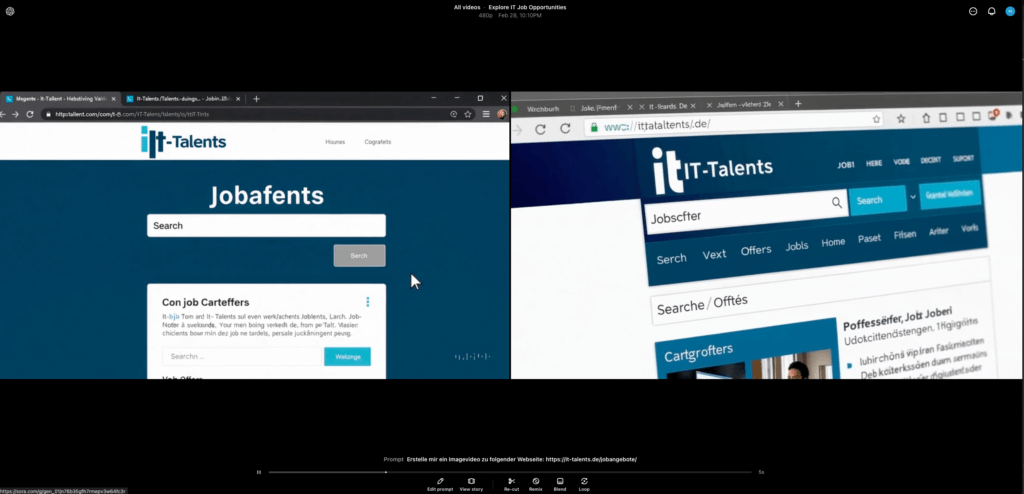
Was direkt auffällt: Die KI erkennt die Webseite als eine Jobbörse und stellt diese auch in der Videosequenz als Webseite dar, jedoch in einem anderen – selbst generierten – Layout.
Auffällig ist, dass Sora hier viel mit der Erstellung von Textsequenzen “arbeitet”. De rText selbst ergibt semantisch aber so viel Sinn, wie bei den meisten per ChatGPT erstellten Bildern: Keinen.
Durch Prompt-Engineering könnte man hier jetzt natürlich beginnen das Video nach eigenen Anforderungen zu gestalten. Wir haben hier nur ein ganz einfaches Prompt mit sehr viel Gestaltungsspielraum verwendet.
Wie arbeitet Sora technisch im Hintergrund?
Sora ist ein hochentwickeltes KI-gestütztes Text-zu-Video-Modell von OpenAI, das auf Deep Learning und fortschrittlichen Transformatoren basiert. Es nutzt Techniken der diffusionsbasierten Bild- und Videogenerierung, kombiniert mit rekurrenten neuronalen Netzen und räumlich-zeitlichen Mechanismen, um realistische Videos aus Textbeschreibungen zu generieren.
Sora arbeitet ähnlich wie DALL·E (für Bilder) oder GPT (für Text), jedoch mit einem speziellen Fokus auf zeitliche Konsistenz und Bewegungsdarstellung.
- Text als Eingabe: Nutzer geben eine Beschreibung ein (z. B. „Ein Hund läuft durch einen verschneiten Wald“).
- Neuronales Netzwerk wandelt Text in ein latentes Videorepräsentationsmodell um.
- Das Modell generiert dann ein Video, das die Szene möglichst genau widerspiegelt.
Technische Erläuterung: Diffusionsmodell für Videos im Detail
Sora verwendet – wie andere Video-KI – ein Diffusionsmodell, das mit Millionen von Videodaten trainiert wurde.
Dieses Prinzip ähnelt der stabilen Diffusionsmethode für Bilder, jedoch mit zusätzlicher zeitlicher Verarbeitung.
Das Modell wird mit verrauschten Videodaten trainiert.
Es lernt dann, dieses Rauschen Schritt für Schritt zu entfernen, bis eine klare Szene entsteht.
Ähnlich wie bei Bildgeneratoren wird der eingegebene Text als Konditionierung verwendet, um den Stil, die Bewegung und das Thema des Videos zu bestimmen.
Der Vorteil bei dieser Technologie ist, dass sehr realistische Details & konsistente Bewegungsabläufe erzeugt werden.
Technische Erläuterung: Zeitliche Kohärenz & Bewegungssimulation
Eine der größten Herausforderungen bei der KI-gestützten Videoerstellung ist die zeitliche Konsistenz: Objekte dürfen nicht von Frame zu Frame „springen“ oder unrealistische Bewegungen ausführen.
OpenAI verwendet bei Sora dazu verschiedene Technologien:
Depth Estimation & Physics Awareness: Bezeichnet die Simulation von realistischen Perspektiven, Tiefeninformation und physikalischer Logik.
Spatio-temporale Transformer: Diese analysieren nicht nur einzelne Frames, sondern die gesamte Sequenz über die Zeit hinweg.
Optical Flow-Tracking: Das Modell lernt, wie sich Objekte im Raum bewegen, um realistischere Animationen zu erzeugen.
Technische Erläuterung: Transformer-basierte Modellierung
Sora nutzt eine weiterentwickelte Transformer-Architektur, ähnlich wie GPT-Modelle für Sprache, allerdings optimiert für Videosignale.
Die Transformer-Architektur bedient sich dabei folgender Möglichkeiten:
-> Latent Video Diffusion Models (LVDM): Eine Kombination aus Transformern und Diffusionsnetzwerken zur Videoerzeugung.
-> 3D-Kernel Convolutions: Kombinieren räumliche (2D-Bilder) und zeitliche (Bewegung) Features.
-> Auto-Regressive Video Prediction: Generiert die ersten Frames und sagt darauf basierend die nächsten Frames vorher, um Konsistenz zu gewährleisten.
Grenzen, Herausforderungen und Bedenken: Sora und Deepfakes?
Wie meistens bei neuen Technologien, geht deren Einführung mit Bedenken, einer Portion Angst und Risiken einher. Besonders disruptive Technologien wie KI, die das Potential haben, nicht nur menschliche Arbeitskraft zu ersetzen, sondern menschliche Wahrnehmung und Entscheidungsfindung zu beeinflussen und – ja – auch zu täuschen, müssen kritisch betrachtet werden.
Deepfake-Problematik & Missbrauchspotenzial
Die Fähigkeit, realistisch aussehende Videos zu erzeugen, erhöht das Risiko von Fake News, Identitätsdiebstahl und Deepfakes. Täuschend echte Bilder und Videos sind bereits mit KI-Modellen wie DeepFaceLab oder Stable Video Diffusion möglich. Sora könnte diese Gefahr deutlich erhöhen, indem auf der einen Seite die Qualität der Deepfakes immer besser wird und selbst “die Physik” im Hintergrund immer besser wird, anhand derer man bisher häufig Fakes enttarnen konnte.
Mögliche Risiken:
- Täuschung der Öffentlichkeit: Politiker oder Prominente könnten in gefälschten Videos Aussagen machen, die sie nie gemacht haben.
- Betrug und Identitätsmissbrauch: Kriminelle könnten gefälschte Videos verwenden, um sich als andere Personen auszugeben (z. B. bei Vorstellungsgesprächen oder Videokonferenzen).
- Propaganda und Manipulation: Regierungen oder politische Gruppen könnten KI-generierte Inhalte nutzen, um Wahlen oder politische Debatten zu beeinflussen.
Um den potentiellen Risiken gerecht zu werden, könnten die Entwickler von Sora (und natürlich allen anderen KI) sich darauf einigen, sichtbare und unsichtbare Wasserzeichen in generierte Videos einzubinden. So könnten Videos im Falle eines Falles immer auf den Urheber bzw. die Generierung durch eine KI zurückgeführt werden.
Das Problem hierbei ist jedoch, dass es einen breiten Konsens geben muss, und sobald auch nur ein KI-Entwickler ausschert, geht diese scheinbare Verlässlichkeit verloren. Ein weiterer Ansatzpunkt wäre staatliche bzw. staatenübergreifende Regulierung, wie sie von verschiedensten gesellschaftlichen Akteuren immer lautstärker gefordert wird.
Urheberrechtsproblematik & Kreativitätskrise
Eine Problematik, die es auch schon mit den GPT-Modellen gegeben hat: OpenAI erklärt nicht restlos, mit welchen Daten die AI trainiert worden ist. Befindet sich unter diesen Daten geistiges Eigentum Dritter (Was durchaus sein könnte), ergibt sich die Frage, ob diese Daten zum Training genutzt werden durften.
Zudem kann man von einer nennenswerten Entwertung kreativer Berufe und menschlicher Kreativität als solches sprechen. Wurde sowohl die Texterstellung, als auch die Bilderstellung und die Videoerstellung bisher als kreatives und künstlerisches Schaffen von Menschen betrachtet, droht sich diese Einzigartigkeit aufzulösen. Die Definition von Kreativität droht sich indes durch die Möglichkeit der maschinellen Generierung von “Kunst” zu verschieben.
Man kann hier durchaus von einer Kreativitätskrise als solches sprechen.
Energieverbrauch & Nachhaltigkeit
Das Erstellen von Videos mit Sora benötigt enorme Rechenleistung, was aktuell zu einem riesigen Energieverbrauch führt.
Ähnlich wie bei GPT-4 oder DALL·E erfordert die Videoerstellung hochleistungsfähige GPU-Cluster, die große Mengen an Strom verbrauchen.
Zwar werden GPUs und KI-Chips immer leistungsfähiger und effizienter, die Anforderungen an diese Hardware steigen aber mindestens ebenso. Ein Lichtblick sind hier erneuerbare Energien, die auf absehbare Zeit eine nachhaltige Versorgung ermöglichen könnten.
Ein weiterer Hebel ist die Weiter- und Neuentwicklung von KI-Modellen, die effizienter arbeiten und mehr Output bei weniger Rechenaufwand liefern.
Gesellschaftliche Auswirkungen: Was bedeutet Sora für den Arbeitsmarkt?
Während Sora große Chancen für Unternehmen und Content Creator bietet, könnte die Automatisierung traditionelle Berufe in der Medienbranche gefährden.
Zeitgleich werden neue Berufsfelder geschaffen.
Ob neu geschaffene Berufsfelder jedoch die Jobverluste in klassischen Kreativberufen ausgleichen können, ist durchaus fraglich.
Vergleich mit bestehenden Technologien: Sora vs. Runway & Stable Video Diffusion
KI-gestützte Videogenerierung ist kein völlig neues Feld – bestehende Modelle wie Runway Gen-2 und Stable Video Diffusion haben bereits erste Fortschritte gemacht. Sora von OpenAI hebt sich jedoch durch die deutlich höhere Qualität, Komplexität und Länge der generierten Videos von der Konkurrenz ab.
Runway Gen-2 vs. Sora
Runway Gen-2 ermöglicht bereits Text-zu-Video-Generierung, ist aber auf relativ kurze Sequenzen (ca. 4 Sekunden) beschränkt.
Die Bewegungsqualität ist oft begrenzt, und längere Szenen wirken weniger flüssig oder konsistent.
Sora hingegen verspricht längere, realistischere Clips mit komplexeren Bewegungen und Übergängen.
Stable Video Diffusion vs. Sora
Stable Video Diffusion von Stability AI basiert auf der Latent Diffusion-Technologie, die auch für Stable Diffusion (Image AI) verwendet wird.
Dieses Modell ist frei verfügbar, aber die Ergebnisse sind oft statisch und weniger flüssig, da das Modell stark auf Einzelbilder ausgerichtet ist.
Sora arbeitet mit einer tieferen Bewegungsanalyse, so dass sich die Objekte realistischer durch den Raum bewegen.
Man sieht: Sora ist durchaus eine Evolution bisheriger KI-Video-Generierung. Aber keine Revolution. Anders als beim Aufkommen von ChatGPT gibt es bereits Konkurrenzmodelle für unterschiedliche Anwendungszwecke, wie beispielsweise den Offline-Betrieb.
Ausblick: Wohin könnte die Reise mit Sora gehen?
Fazit: Chance und Risiko zugleich
Sora ist ein weiterer Meilenstein in der Welt generativer KI. Das disruptive Potential ist riesig, erste Ergebnisse sind durchaus beeindruckend. Aber mit dem enormen Potential gehen auch enorme Risiken einher.
Wir haben endgültig einen Punkt erreicht, in dem KI nicht nur in der Lage ist, Arbeitsschritte effizienter zu gestalten, sondern es können auf absehbare Zeit ganze Berufszweige verschwinden. Das ist nicht neu und seit je her Ausdruck technischer Evolution, aber es birgt in der atemberaubenden Geschwindigkeit auch sozialen Brennstoff.
Zudem stellt sich die Frage, ob wir als Gesellschaft in so kurzer Zeit wandlungsfähig genug sind, diese neue Technologie verantwortungsvoll einzusetzen ohne zugleich den gesellschaftlichen Frieden zu riskieren.
Aber es wird wie so oft sein, Technologie, die dem Menschen – vor allem mit so geringen Schwellen – zur Verfügung steht, wird auch genutzt werden. Es ist daher umso wichtiger, dass wir als Gesellschaft über die Möglichkeiten, aber auch die Risiken generativer KI – vor allem im audiovisuellen Bereich – aufklären und so das Missbrauchspotential untrer Kontrolle behalten.
Die eigentliche Gefahr ist keine übermächtige, sich verselbständigende KI a la “Skynet”. Die größte Gefahr ist der unverantwortliche oder gar destruktive Einsatz dieser Technologie durch Menschen, die zu einer Destabilisierung unserer Gesellschaften führen kann.
Rückmeldungen